
DeepSeekR1绝非昙花一现!它以突破性技术,大幅降低AI成本,并开源顶尖模型,重塑全球AI格局。更重要的是,它为中国AI应用爆发注入强劲动力,国内AI产业迎来前所未有的机遇。
这篇文章,我将深入解读DeepSeek的意义与价值,为你揭示AI投资新风向。读完此文,你将快速看懂DeepSeek,把握AI投资大趋势!
1)DeepSeek是否“昙花一现”?
2)谁是DeepSeek的受益者?投资关注哪些领域?
创投圈里最大的“AI黑粉”朱啸虎,已经倒戈要投AI了。

一、DeepSeek是持续影响还是“昙花一现”?
我认为这次DS将给AI应用带来持续影响,不再是短期炒作。
具体类比如AI带动了美股的GPU芯片,是实际影响。
我从以下几个角度来拆解DeepSeek R1带来的变化。
1、DeepSeek在技术层面对全球AI的影响,非常积极:
首先,DeepSeek轰动世界的是两个模型,而不是一个,分别是
DeepSeek-V3:这是个基础模型,快思考模式(没有思维链)。
DeepSeek-R1:这是个在V3之上通过纯强化学习(RL)技术获得的推理模型,慢思考模式(有思维链)。
然后,我们来理解这两个模型的含义。
V3 —— 基础模型,重点在“预训练”,就像我们让脑子掌握各种基础知识、大数据。
基础模型中,最大名鼎鼎就是GPT-4,预训练花了非常多的钱,并且OpenAI每升级一版基础模型,模型参数就要放大10倍,投入的算力资源增加100倍,结果是基础模型的能力更强。
这就是Scaling Law,是之前人们认为,在训练模型时必须大幅增加算力,接受烧钱的根本原因。
而DeepSeek-V3带来的突破是:
创新使用多头潜在注意力(MLA)机制和负载均衡策略,让基础模型在预训练阶段提升同等能力的情况下,需要的算力成本大幅下降。
这就是大家在新闻上看到的那句话的含金量:
“DeepSeek预训练仅需266.4万H800 GPU小时,训练成本压缩至OpenAI同类模型的1/30,V3以约557.6万美元的训练成本实现了与GPT-4o、Claude-3.5-Sonnet等顶尖闭源模型相当的性能。”
R1 —— 推理模型,重点在“后训练”。这是在基础模型V3之上,通过强化学习(RL)来激发V3展现出更强能力。就像我们掌握丰富的知识后,学习方法论、思维框架、把经验提炼成理论,来更好的指导未来的实践。
类似的模型如OpenAI的o1、o3,也是推理模型,它们是在基础模型GPT-4的基础上通过“后训练”来获得的。
基础模型(如V3、GPT-4)是脱口而出的回答。
推理模型(如 R1、o1)是深思熟虑后,再回答。
深思熟虑的答案质量,会明显上升,但代价是思考环节需要消耗更多算力、回答速度变慢。
但这依然非常有意义,因为答案的质量永远是第一位的,其次才是速度,这也是AI能真正应用到日常生活中的核心前提。
深思熟虑质量好的前提是,你的基础知识必须质量好。
即,推理模型想要通过“后训练”方式获得更强能力的前提是,它的基础模型能力必须足够强。
通过“后训练”让模型学会“深思熟虑”这件事,是OpenAI的o1模型最早做出来的,因为它有当时最好的基础模型GPT-4。但OpenAI为了保持领先和商业利益,并没有开源它的代码和技术,而是在公布技术时留了“谜语”,其他人只能靠猜测和尝试,去复现它的效果。
并且,之前大家使用的主流训练方式是监督微调(SFT),只有极少数企业坚持使用强化学习(RL),因为RL相比SFT,见效慢、成本更高。
而DeepSeek-R1带来的突破是:
它率先破解了OpenAI的谜语,并且通过开源,把答案公布给了全世界。
即,在“后训练”过程中,使用强化学习(RL)这条路,可以走的通,并且具体如何走也公布给大家。
而且强化学习(RL)这条路的能力上限比监督微调(SFT)更高。
总结一下:
DeepSeek用V3模型,证明了提升模型能力,不必只信仰“猛堆算力”,而优化算法同样可以达到相等的效果。(之前业内也有这种期待和研究,但DS是第一个成功做到的)
DeepSeek用R1模型,证明了“后训练”这条路可行,并且用强化学习(RL)进行“后训练”可行,它为这个研究方向提供了强有力的确定性,让之前犹豫不决的开发者都能更集中资源、聚焦在这条路上进行突破。
并且,DeepSeek把V3和R1模型都开源了,全世界的人都可以免费拿来研究提升。本来这种尖端能力只会被OpenAI几家全球顶尖的闭源公司掌握,但现在DS凭一己之力,用极低的算力成本,把全球AI的能力都直接提升到了接近OpenAI-o1的水平,这对全世界的贡献是非常巨大的,对于所有研发人员来说,都是巨大的振奋。(但OpenAI等之前的顶尖公司会感到巨大压力)
最直观的证据:DS在GitHub上获得的星星超越了OpenAI,这是开发者们用脚投票的结果。

2、DeepSeek对中国的意义远大于对全球的影响:
很多人看到我们扬眉吐气,会本能的兴奋,甚至变得有些“目中无人”。
但是:
DeepSeek超越OpenAI、谷歌等一众公司了吗?
很遗憾,还没有。
目前能力最强的AI模型,依然掌握在这三家手中:OpenAI、Anthropic、Google。
DS引起轰动后,OpenAI迅速放出了o3系列模型,Google也放出了Gemin2.0 Flash Thinking模型。
这些模型在推理能力上,依然是顶级水准。
DeepSeek的模型是全球性价比最高的模型吗?
很遗憾,也不是。
谷歌最新的Gemin 2.0相关模型,使用价格比DS的模型还要便宜,能力也更强,这对真正使用AI做产品商业化的人来说,可能比DS的性价比更高。
但DS的突破,对我们中国来说意义非常重大!
使用AI模型的人,主要分两类:
一类是个人用户,解决日常工作问题。
一类是企业用户(个体户),通过给产品嵌入AI用于商业化。
在此之前,国内没有任何一款模型可以在能力上与全球顶尖模型“掰手腕”。
大家可能看到各种跑分,说自己的模型追赶上了谁谁谁,一笑了之即可。
此前,国内没有任何一个模型可以取代OpenAI的GPT(而对于写代码的人来说,Anthropic家的Claude模型就是最好的)。
这一点但凡真正体验过顶尖模型的人,应该没有异议。
但在DeepSeek –R1出现后,我觉得能力上,真的可以替代相当一部分了。
还是前面说过的:“答案的质量永远是第一位的,其次才是速度,这也是AI能真正应用到日常生活中的核心前提。”
DS这次让无论是个人用户,还是企业用户,都有了我们中国自己的顶尖大模型可用。
之前国内的AI企业只能选择出海,因为国内模型能力不行,而国外顶尖模型不让国内用。
但现在,意味着国内的AI应用可以在国内开始做“井喷式”的尝试了。
从现象来看也是如此,DS的R1模型从春节上线至今,其官网的流量几乎时时处于撑爆的状态。
各大云厂商(华阿百腾电联移金等)几乎在第一时间宣布适配了R1,但基本谁上线R1,谁家就会卡住。
包括大疆在内的各种包含算法使用的公司也第一时间部署了R1。
你在小某书上可以看到铺天盖地使用DS的玩法教程。
DeepSeek在上线20天后,其日活跃用户数(DAU)迅速突破2000万大关,成为全球增速最快的AI应用。之前获此殊荣的,是首次上线的ChatGPT(上线2个月不到的时间突破1000万DAU,在20天2000万面前,竟然略显平淡)。
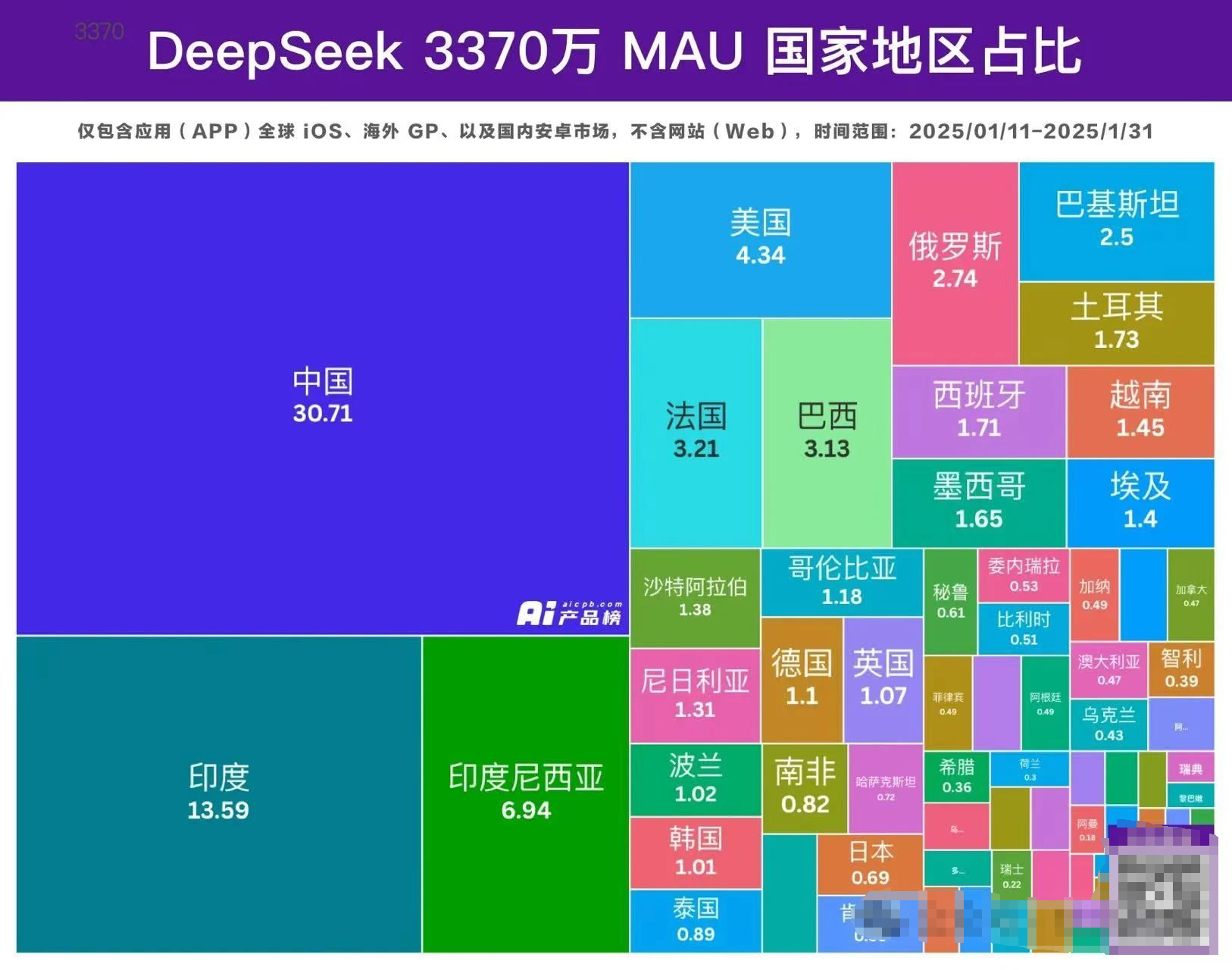
从格局上看,美国的顶尖公司在推进基础模型能力方面,确实让人敬佩。
但要说在应用层面,中国从来都是世界第一。
这一点在移动互联网时代就已经奠定了,我们有全球最大的To C消费市场(观察用户反馈和多样性)、海量的顶尖人才、最“勤奋”的工作态度,代表我们能做出最让消费者满意的应用产品。
看看TikTok在国外被追捧的程度、最近涌入小某书的老外,这点自信大家还是要有的。
总之一句话:
在有了我们自己的顶尖大模型后,谁能在AI应用商业化大潮中笑到最后,尚未可知。但我们作为消费者,一定能等到那款让人惊艳的现象级AI应用,它极大概率会出现在中国。
回到前面的那个问题:DeepSeek是持续影响还是“昙花一现”?
我认为是持续影响,并且对我们国内的影响将远大于国外。
DS通过创新+开源,让全球AI水平上了一个台阶,拉近了与顶尖模型的身位。
DS让国人有了自己的“高能力+低成本+开源”模型,让国内AI应用商业化尝试正式加速。
二、谁是DeepSeek的受益者?
想清楚这个问题,会决定我们将投资目光重点投向何处。
无论是V3还是R1,它都是一个开源模型,意味着谁都可以来用,来研究。
DeepSeek活菩萨,它虽然增加了影响力和品牌效应,但它本身是无法靠这个模型赚钱的。
1、国产芯片:
接下来,我们必将迎来更严峻的算力进口阻碍,但这次DS的模型另一个厉害之处在于,其运行对芯片制程要求不高。
所以,国产芯片这次是真的可以供应运行DS的模型。
目前菊厂的910C已经完成适配,供大家使用DS了,相关的产业链可能获益。
但今年开始,半导体出口美国的关税将提高到50%,对于整个行业来说有此消彼长之感。
而且DS本身节约算力成本的特点,对美股算力芯片的情绪打击不小,国内在算力炒作上可能也心存谨慎。
综合来看,国产芯片未必会是最有爆发力的那个,但它必然在行情轮动的逻辑链条中占据一席之地。
2、云计算:
从各大云厂商“火急火燎”适配R1就知道,这对它们非常重要。
而在炒作逻辑方面,直接对标美股的云厂商(微软、亚马逊、谷歌、甲骨文)。
因为有更多人使用AI模型,而他们没有能力在本地部署(对个人和中小企业来说算力成本高),所以会从云端调用模型,这就会消耗云厂商的算力,产生费用,形成云厂商的收入。
OpenAI等闭源模型公司要部署在云厂商上,是因为云厂或者是这些AI公司的直接投资人,或者支付费用。
但DS是开源的,国内云厂商可以直接免费拿来部署,再供其它人使用。
这会导致两个结果:
1、对云厂商来说,模型几乎是无成本的。
2、对各大云厂商来说,因为获取模型没有成本和门槛,云厂之间可能陷入价格战竞争。
但需强调一点,无论国内国外,无论大模型本身的算力消耗如何下降,未来对整体算力需求继续提升的大趋势是明确的。
无它,因为全民使用AI的时代还没有到来,真正庞大的算力需求来自于全球上亿用户每一次日常调用,而不是训练模型的环节。
因此,如果相信AI应用的爆发将会到来,那么对云计算的需求就不会少。而云厂商如果要扩大算力基建,就需要国产芯片、服务器等相关算力基础设施,它的需求会传导到相关硬件厂商那里。
3、AI应用:
这是一个非常宽泛的领域。AI模型公司可以研发应用产品,软件应用公司也可以嵌套AI模型。
一切的前提都建立在AI模型的能力足够强这个基础上。
就目前DeepSeek-R1模型的能力来说,已经足够支持去做更多AI应用的探索了。
我们接下来会看到“AI应用”与另外一个词高频相伴出现 —— Agent。
Agent的本质就是调用各种其它类型的模型或工具作为“手和脚”,由R1这样的模型作为“大脑”发出指令,去帮助用户自动完成某些任务。
从我观察来看,用户对大模型本身是“没有忠诚度”的,谁的模型更好用、性价比更高,谁就会更受青睐。(之前GPT一直独当一面,是因为没有对手,后来Claude从GPT手中抢走了写代码的程序员,现在R1将从GPT手中抢走一部分不愿意支付高额费用还要受到使用限制的用户)
未来当大模型的能力都高到足以应付日常大部分问题的水平,并且价格便宜到大部分人都可接受的程度后,大模型的护城河将消失,陷入纯粹的价格战。(除非某家模型公司能一直保持能力领先,让人不得不使用它,但这很难,当前的OpenAI的处境就是典型案例)
而真正的护城河,或许在于个性化、定制化,它需要的是独家的垂类数据库。(比如个人的使用习惯、某个特定群体的特点、某个特定领域的高质量小众数据等)
目前有很多AI应用企业都专注于“垂类数据库+AI模型”,它们通常都是某些行业内的信息化平台,能够拿到各种用户数据,这些企业通常属于To B端。
而To C端,最容易让人想到的就是国内几家大型电商、互联网平台,手握海量用户数据。这其中,谁的生态链最完整,最有可能笑到最后。
生态链完整,意味着它能获得用户数据的同时,还能更容易的把产品提供给用户的方方面面。
在美国,谷歌为了在智能手机出现的移动互联网时代对抗苹果,选择了买下安卓系统并开源,搭建自己的生态。苹果的IOS系统本身就是一个巨大的封闭生态,全球的苹果用户都在为它创造巨大价值。
而在我们中国,大家能想到哪些公司呢?答案呼之欲出吧?(腾阿抖京米华美百……等)
个人用户,不是为了研发产品赚钱,只是为了让日常变得更高效,也可以自己去尝试创建Agent。现在有了R1,收集自己的数据库,搭建自己的Agent的门槛已大幅降低。“遇事不决问R1”,应该会成为积极拥抱互联网的年轻人的常态。而这也将增加算力需求,符合上面云厂商的受益逻辑。
总结:
1、DeepSeek不是昙花一现,它对全球,尤其是中国影响巨大。
2、行业关注国产芯片、云厂商、AI应用/互联网平台,我最看好的还是从AI应用中的潜在机会。
3、不要只当投资者,去作为用户使用R1吧!它会帮到你的。
—— 以下是:股市消费记录 ——
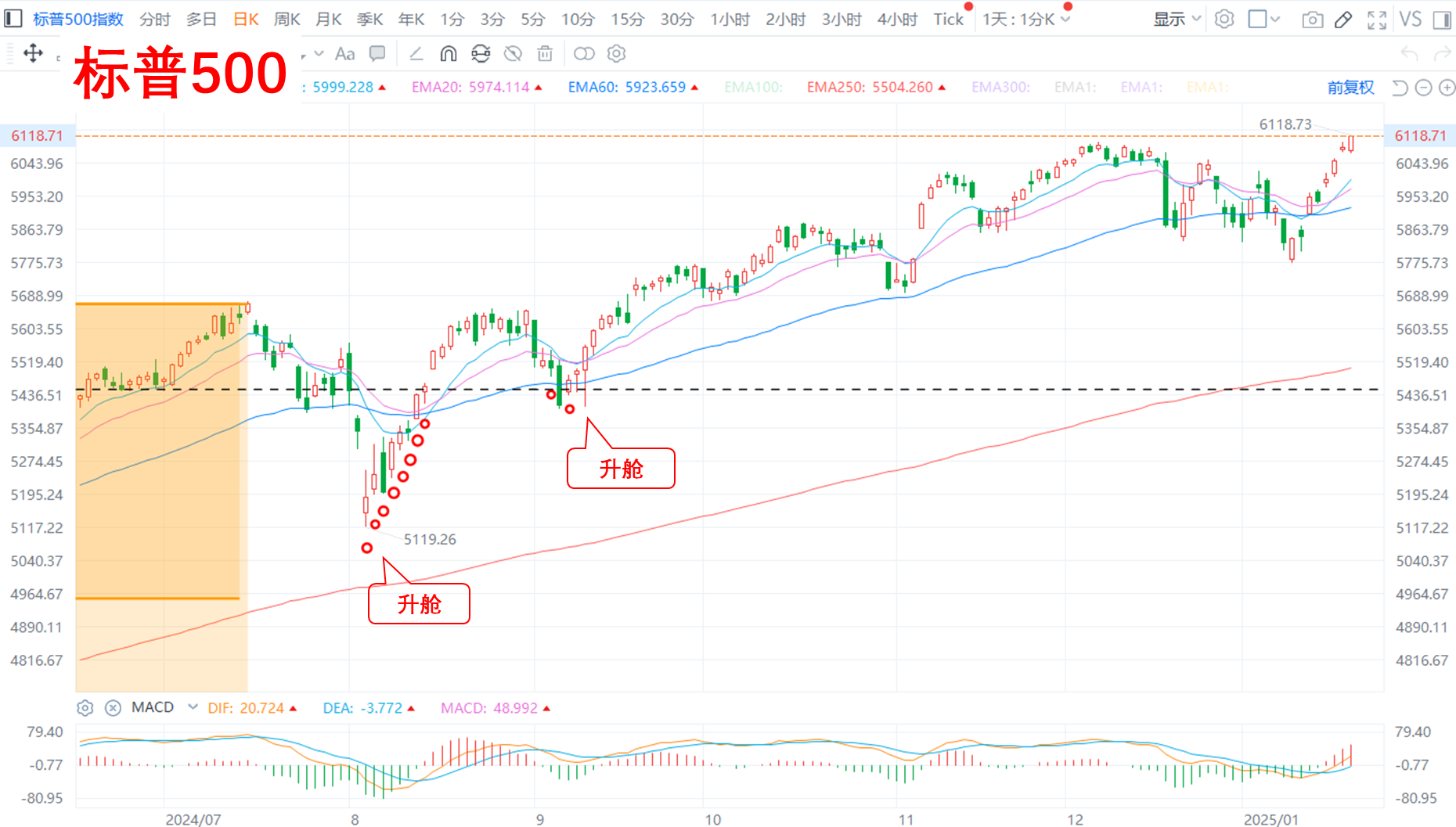
美股:
**标普:已成非卖品。
**纳指:无。
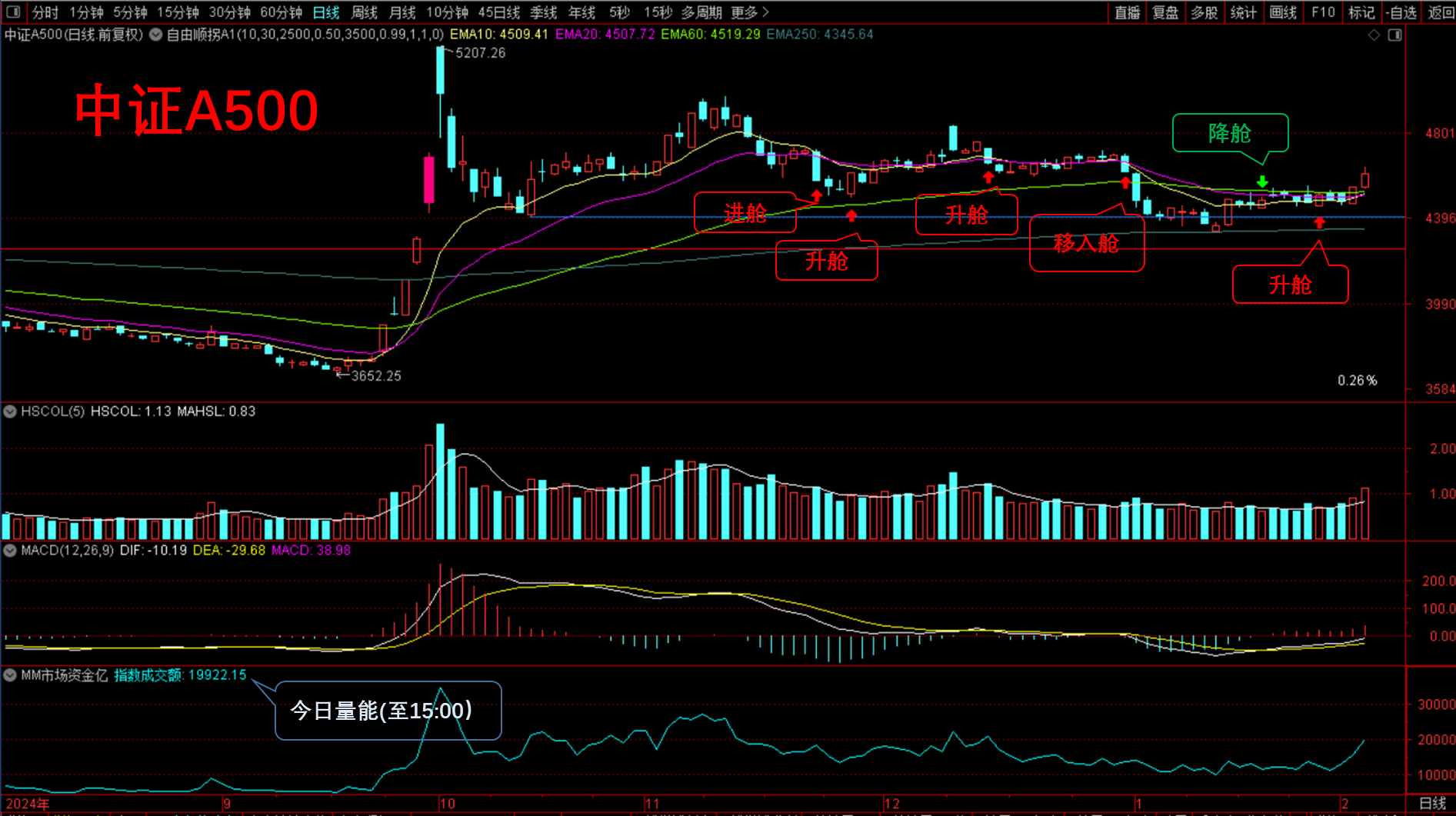
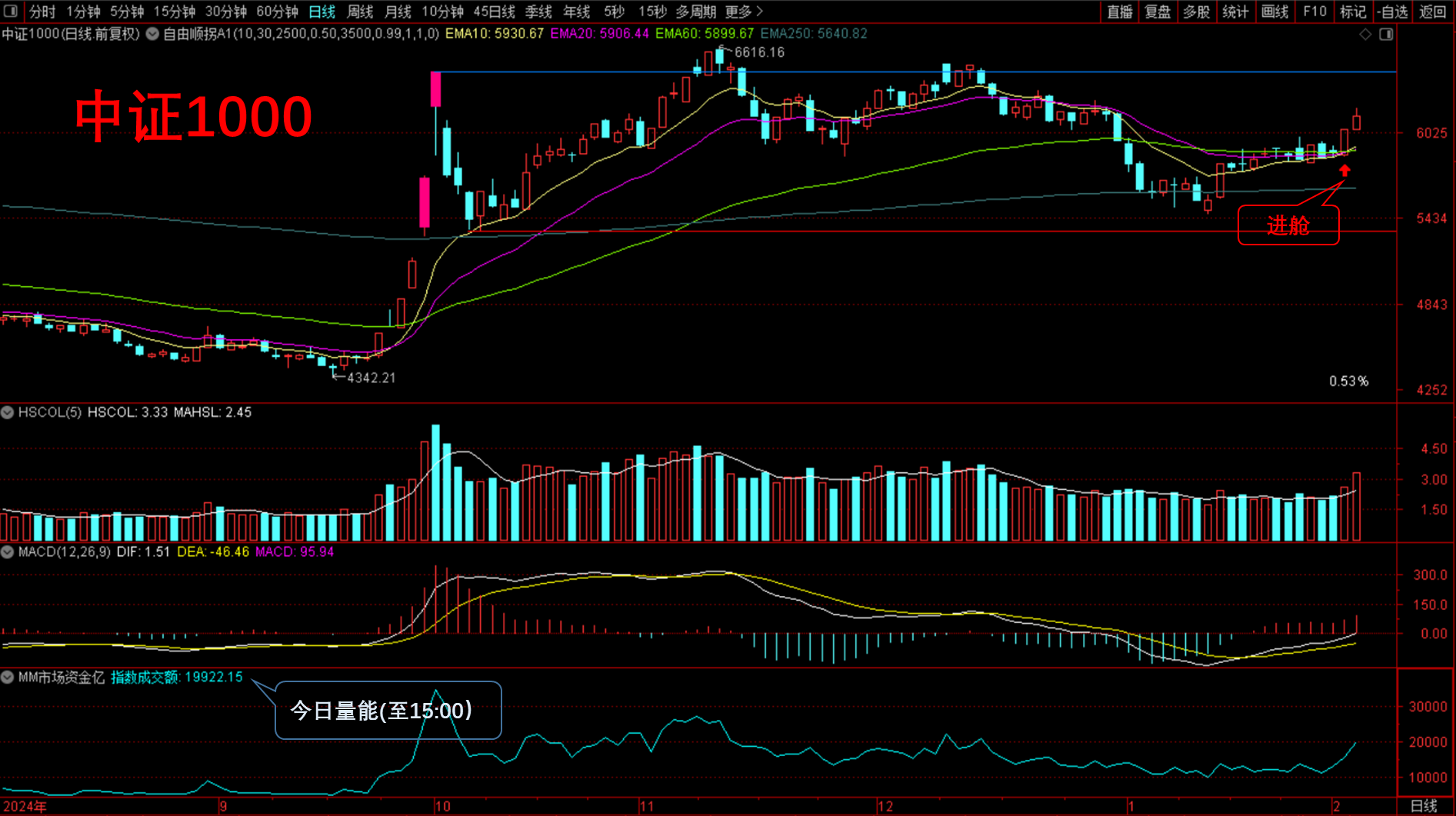
国内:
**中证1000:春节后建舱。
**中证A500:保持基本舱。
*** 做合格金融消费者,从记账开始!***
海外消费记录:
国内消费记录:
< 分享增量信息,提升决策质量。记录真实消费。如果你感兴趣,欢迎点赞关注,留言讨论,咱们交个朋友。>
风险提示:以上为个人观点,不构成买卖建议。市场有风险,投资须谨慎。
$南方中证1000ETF发起联接C(OTCFUND|011861)$
$易方达中证1000ETF联接C(OTCFUND|016631)$
$易方达上证科创50联接C(OTCFUND|011609)$
$易方达上证科创50联接A(OTCFUND|011608)$
$天弘创业板ETF联接A(OTCFUND|001592)$
$天弘创业板ETF联接C(OTCFUND|001593)$
$易方达创业板ETF联接C(OTCFUND|004744)$
$易方达创业板ETF联接A(OTCFUND|110026)$
$华夏科创50ETF联接C(OTCFUND|011613)$
$华夏科创50ETF联接A(OTCFUND|011612)$
#高盛德银齐唱多A股,你怎么看?##DeepSeek火爆全球,对A股影响几何?##人形机器人板块大涨!能追吗?##黄金再创历史新高 你怎么看?##黄金大涨,能否持续?#
