
#新年投资计划##Deepseek顺风车#
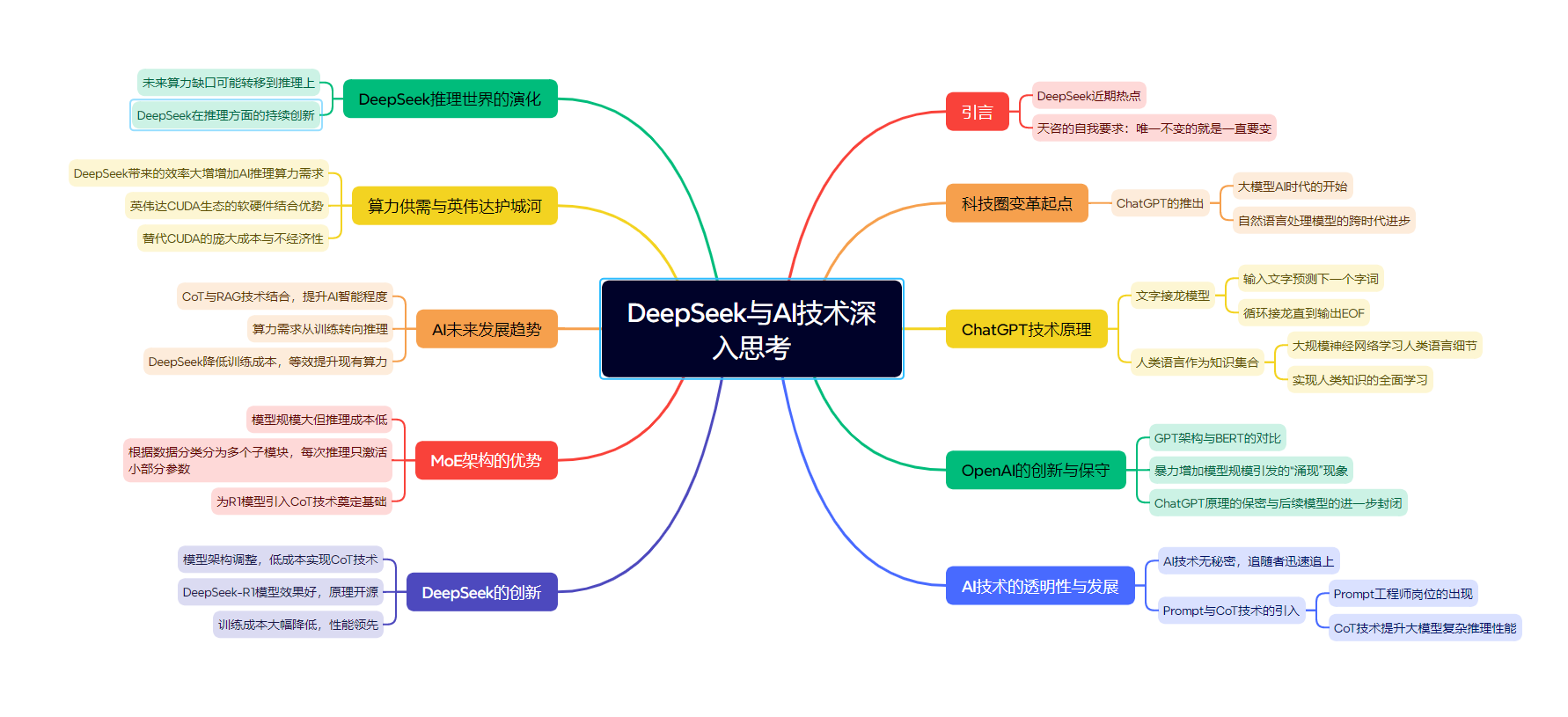
近期科技圈最大的热点就是DeepSeek了,deepseek+医疗,deepseek+算力,deepseek+腾讯......热点几乎一天一个变化。天咨一直以来对自我的要求——唯一不变的就是一直要变。对于认知,依然如此。因此,我想深入谈一谈deepseek横空出世以来我对科技的深入思考:
天咨认为,要谈deepseek,就不能仅从DS开始,如果时间再拉长点,近三年科技圈最大的改变就是从引爆世界的ChatGPT开始的浪潮,全世界都相继进入了大模型AI时代。

在ChatGPT之前,AI做自然语言处理的模型也一直在进步效果远没有到惊人的程度,ChatGPT推出时的表现可以说是跨时代、令人震惊的程度。天咨之前看过对OpenAI创始人的访谈,设计ChatGPT的思路其实是非常玄妙的,如果你单看大语言模型的原理,你会觉得摸不着头脑。目前市面上所有的大模型,原理都是文字接龙:你给它输入一段文字,它只是预测这段文字的下一个字或词是什么(这个字或词称之为token),字词输出后程序会把它输出的单个字词拼到你输入的这段文字后面,然后将其再作为输入让模型去预测拼接后的这段话的下一个字词是什么,模型不断循环接龙,直到模型输出EOF(结束标记)为止。
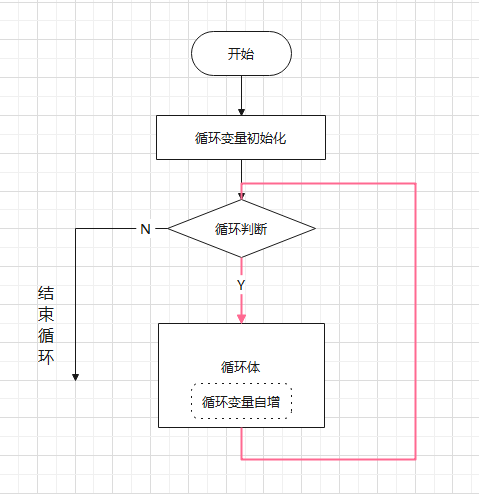
大模型的训练也只是让神经网络去学习文字之间的关系、学习预测一段话下一个字的概率而已。为什么一个词语接龙的程序却能上你和它对话、让它帮你思考复杂问题,仿佛有了智慧和意识一样? OpenAI当时认为,人类千年来的知识其实都汇聚在人类语言中,任何知识都可以被语言所描述,那么实际上人类语言可以认为就是压缩了全人类知识的一个集合。那么用一个大规模的神经网络去学习人类的语言细节,有没有可能就能让其学会人类所有的知识呢?
这完全是一个天马行空、失败代价极高且很可能失败的想法,没有人做过这种尝试。当OpenAI把这个思路实现落地后就是当年震惊世界的ChatGPT3。
至今为止,市面上的大模型也没有跳出这个思路和方法,大家通过不断地优化训练数据、神经网络结构、引入新的改进和优化方法,大模型的智力越来越高了,人们仿佛看到了下一次技术革新的曙光。
但OpenAI一点也不"Open", GPT架构其实可以视作是Google的BERT架构的精简,早期的GPT效果是不如BERT模型的, GPT和BERT也都是完全开源的模型。OpenAI的尝试发现了一个现象:如果暴力增加模型规模, GPT模型会在某个之后出现"涌现'现象。也就是模型规模达到一定程度,突然模型就聪明了一大截,仿佛顿悟了似的。到此推出ChatGPT, 但OpenAI只是用论文描述了原理,并没有开源ChatGPT的任何代码。再到后来, OpenAI连新模型的原理都藏着,甚至你在ChatGPT上问它新模型的原理实现都有可能被封号。
不过技术创新最重要的是初始的那个想法,大模型训练的成本是很高的,当年没有人敢试错,OpenAI告诉了大家这条路可行,后续追随者们很快就追上开源了自己的大模型。

换言之,站在今天看,AI技术在业内其实没什么秘密,你就是藏着掖着捂着,别人也总能慢慢追上你的水平,除非你一直保持技术探索产出的高增长。DeepSeek就是一个很好的例子。由于大模型的原理是文字接龙,因此你和大模型对话前置输入的语句就非常重要,在业内这个前置语句被称为Prompt'或提示词”,只有你熟悉对应模型的特点,针对性的调节提示词才能最大化地引导增强模型的输出效果。甚至前两年出现了“Prompt工程师”这样的岗位:单纯利用技巧去调输入什么和大模型对话效果最好就可以在一线城市拿到上万的月薪。
而ChatGPT的o1模型引入了一个被称为CoT (思维链)的技术,这里补充一下它的定义便于大家理解。
定义与原理 CoT,即Chain of Thought,是一种Prompt提示技术,旨在提升大型语言模型(LLMs)在复杂推理任务中的性能。它通过在问题和答案之间插入中间推理步骤,模拟人类解决问题时的逐步思考过程,以提高模型在算术推理、常识推理和符号推理等任务中的表现。
用户不需要再千方百计地测试如何对话效果最好,而是大模型本身就可以通过用户输入的简单语句来推测用户的意图、回答的要点、注意的事项,形成一个“思考的链条”,这个思考的链条因为包含了大量的注意项、关键要点,因此便可以成为这次对话的提示词。这项技术能大幅提升大模型的输出效果,因为它能快速生成一个不错的提示词,最大程度地激发模型的潜能。OpenAI对这项技术的原理讳莫如深,仿佛这就成为了它的独家护城河。
但AI技术没什么秘密,各家都在钻研CoT如何实现,这个方向几乎也是业界共识。DeepSeek这次在模型架构上做了一些调整, 率先低成本地实现了这项技术,DeepSeek-R1模型的效果很好,并用论文详细解释了它的原理并开源了模型。
DeepSeek这次最亮眼的点是用小一个数量级的训练成本训练出了头部大模型类似的性能,并且在有些测试上还略微领先。这证明了目前业界主流的大模型训练的优化上可能还有很大的进步空间。
实际上这次DeepSeek是火到出圈了,因为训练成本高昂一直是大模型的共识。其实去年DeepSeek就因为成本震惊过一次业内,因为它走的MoE架构非常成功,相比之下会节省很多推理算力,它去年就实现了业内几乎最低的推理token价格,而这为今天的R1模型其实已经做了铺垫。
所谓MoE架构是指:模型虽然规模很大,但是它可以根据数据分类被分为多个领域的子模块,每次推理只激活一小部分参数权重,就和大脑不同功能的分区一样。传统大模型假设有1100亿参数,它每次推理是需要全参数协同计算的,1100亿已经是一个对算力要求很大的规模了,效果非常好的模型规模也一直在700-1200亿之间徘徊。而DeepSeek的主力模型量有6700多亿参数,但它每次只会激活其中的370亿参数,尽管显存占用很大,但对GPU算力的消耗其实要小很多。以至于它在1TB内存的电脑上用CPU推理都是可以进行稍慢对话的程度。
为什么说MoE架构给今天的R1模型留下了铺垫呢?因为一旦引入前面说的CoT技术,推理成本就是影响模型效果的关键因素了。OpenAI其实已经发现了在推理过程中,CoT思维链越长、越细,几乎越是能成正比地提高模型的智力水平。但CoT是非常消耗token数量的东西,换言之就是非常贵。为什么ChatGPT-o3模型难产?因为这玩意太慢了,而且资源消耗太大了,完全是用钱烧出来的逆天效果。
在此之前,业界有一种论调,认为目前大模型效果取决于模型规模,而模型能产生效果的规模和训练数据规模挂钩。而目前训练的大模型已经把人类能找到几乎所有的信息都训练进去了,很快大模型规模就会到瓶颈,那么模型效果也就只能原地踏步了,那AI的故事就讲到头了。但实际上大模型CoT是开辟了新思路的。
举一个通俗的例子:如果只是对话和简单思考,人脑其实不比大模型强多少,可能未来大模型对话能力的极限也就是到人脑这个水平了。但这不妨碍人类同样可以做复杂的科研、复杂的知识推演:你无法心算两位数的乘法,但不影响你可以探索数学高峰。
其实在2023、2024年两年里,大模型理解超长上下文的能力就已经很强了,因此引入CoT后,未来大模型可以通过不断增加CoT的长度以及配合RAG技术(让大模型可以利用外部的工具)来做非常深度地、利用外部工具地复杂思考,如果这么想的话,那么其实未来AI效果提升的空间会很大。
当然这会耗费大量的推理算力,过去卷训练的大量算力资源可能就去到推理层面了。可是去年DeepSeek就把推理成本打低了,搞得当时阿里的qwen 1.5后来都去做了一版MoE的模型。所以这次R1模型加入CoT后的推理成本依然是可以被接受的。因此DeepSeek近期的工作可以说是在保证效果甚至提升效果的情况下,把大模型训练和推理的成本都降低了一个数量级。在DeepSeek这种疯狂卷成本到白菜价的情况下,就可以轻易倾泻token长度在CoT 上肆意拆解问题来提升效果了。
由于AI业内没有秘密,很快DeepSeek的思路就会在全世界的大模型上被利用起来。这是不是说明未来算力就不会再吃紧?一众搞算力的公司带着英伟达全部被按在土里了呢?
我是不这么认为的。纵观整个神经网络AI发展的历史,实一直以来就是依靠“大力出奇迹”发展和突破的。

早在二战后就提出了人工神经网络技术,当时的研究停滞在人工设计的神经元根本无法处理复杂的关系,资源消耗又很高,完全不如概率模型。后来发现原来神经元只要搞很多,似乎还是能解决问题,但当时的电脑已经不支持干这个事了,太不经济了,AI就到了天花板。

本世纪以来,计算机算力大幅提升,人们又捡起了神经网络这套东西,发现如果搞很多层的神经元,神经网络效果又能上个大台阶,当年AI时代主流的基于概率的模型迅速就被深度学习模型所替代了。
到了近5年,实大模型核心的Transformer架构也不是多新鲜的事,它并没有和传统的LSTM一类的架构拉开多大的差距,结果OpenAI去硬堆网络参数规模,没想到涌现出了ChatGPT。
当现在大模型参数规模也快到瓶颈的时候,又凭什么认为这是历史的终点呢?大力出奇迹在AI界那几乎就是历史常态,现在的DeepSeek R1和ChatGPT O系列模型本质上走的是一个路子:就是用长长的CoT把问题切成细粒度的一步步子问题。然后再组合起来形成思考结论。那么其实只要舍得卷token长度,把CoT往长了搞,几乎就是增加AI智能程度的版本答案了。
如果CoT足够长、如果中间加入了RAG,那么是不是AI地可以去可靠地做一些极其复杂的工作了呢?例如:可以做前沿的科研工作、可以在大量行业解放大量的人工的同时提升效能。会不会可控核聚变技术最后是被AI深度思考攻克的呢?
因此DeepSeek把大模型的训练和推理成本打下来十倍会导致算力冗余吗?并不会,这件事本质上是现有算力等效提升了10倍,这就会出现更奢侈的CoT或以前不敢想的算法,从而追求更高的智能。
举个通俗例子:假如明天科学家突然宣布’核聚变充电宝”上市了,电费直接打一折。这时候你会满足于只给手机充电吗?当然不会!你肯定要开着空调盖棉被,家里有老人的,甚至还会将冰箱插头插在充电宝上,出门旅行时直接把家里电闸关了......可以电表不走字了。
这就引出一一个神奇的经济学定律:杰文斯悖论。1865年有个叫杰文斯的英国经济学家发现,瓦特改良蒸汽机后,明明烧煤效率提高了,结果全英国的煤矿老板反而加班加点挖煤。这就像油车换了辆电车,结果因为电费太划算,天天开车去买奶茶、出去逛、到处跑,最后用车公里数比以前高多了。
类似的现象在人类史反复上演:燃油效率每提高10%,马路上的汽车就会多出15%。LED灯比白炽灯省电80%,结果现在商场可以用灯光把整栋楼变成赛博霓虹灯。除此之外,可以非常容易地预见到,大模型引入CoT后,其实在很多场景下是不需要/不希望显示这个思维链思考过程的。比如你和客服机器人对话,总不能机器人给你显示一大堆它是怎么想的吧?但你如果原封不动地隐藏这个过程,对用户的表现就是机器人很卡,一天没有反应。
而CoT目前这又是必须的一步且非常消耗token。那么在很多场景下为了在可用的速度下不显示思考过程。推理算力可能要增加很多倍才能达到和以前差不多的效果,那么实DeepSeek降低的训练算力即使全堆给推理用甚至可能还不够。
因此从供需角度来分析的话,DeepSeek带来的效率大增反而会增加AI的推理算力求。那么供给侧是不是意味着英伟达的神话还能继续呢?这就要提到英伟达在AI时代的两个独特的护城河了: CUDA和多卡通信。
CUDA其实有,点类似于iOS,它是一个软硬结合的产物,于历史悠久的先发优势,CUDA生态已经形成,目前这个护城河还没有被打破的迹象。长久以来, AI方面主流的、好用的开源生态全部依赖于CUDA环境,别家进驻基本上等同于软件层面要从0重写一遍基于CUDA的底层API,而且有的底层算子非常依赖于GPU硬件设计,即使在英伟达的平台运行,很多AI库会去识别运行的GPU型号来选择用哪套算法运行。这类算子是无法移植的,只能针对性重写。
因此要替代CUDA是一个非常庞大且需要用户、开发者都付出额外代价非常不经济的行为,这个商业壁垒还没有被打破。
不过DeepSeek改变了算力的一些应用方式。过去缺算力主要是缺训练算力,英伟达被禁售后,训练大模型需要的动辄万卡的高性能计算集群就成了香饽饽。但显然未来的算力缺口很可能转移到推理上。因此,DEEPSEEK的推理世界依然在演化......
我们再来看一下市场上相关产品:
我们测评一下万家中证软件服务ETF发起式联接A:$万家中证软件服务ETF发起式联接A(OTCFUND|018182)$
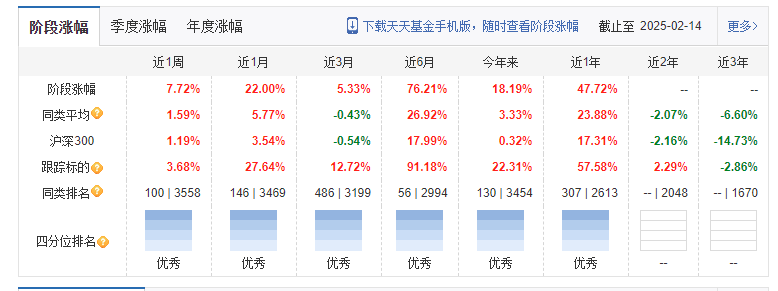
从阶段涨幅来看,该基金各周期均处于优秀象限。
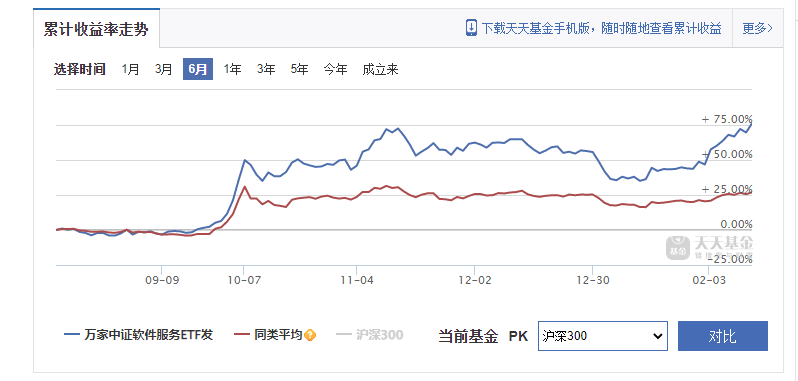
从累计收益走势图中我们可以看到,近半年来,该基金收益率较大幅度领先同类平均水平。

对于被动式基金,其费率较低也是投资朋友们所了解的,从上图可以看到,该基金运作费率为0.6%,低于同类平均的1%。
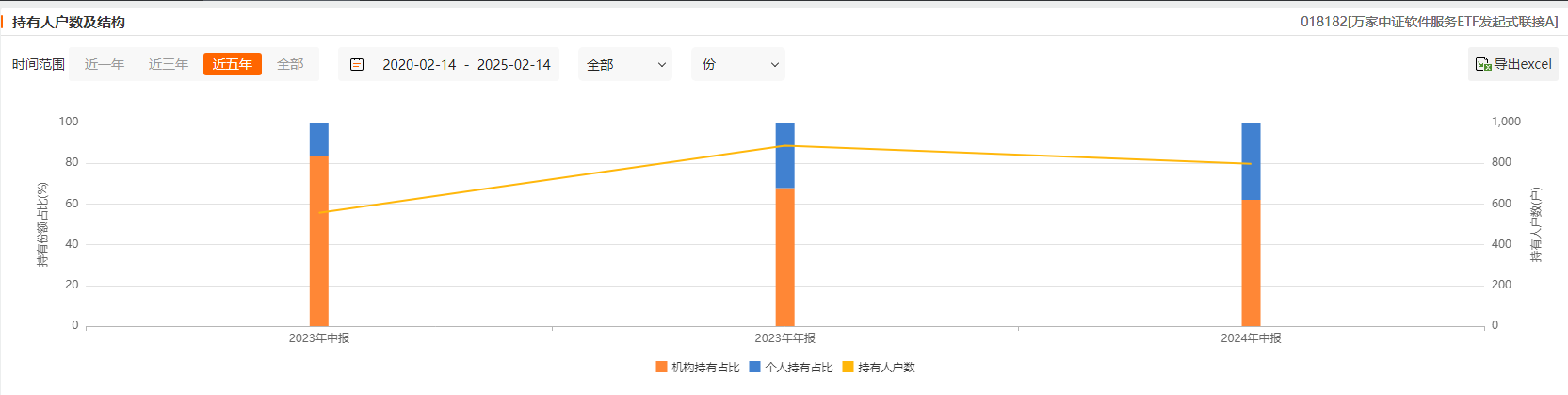
从持有人结构可以看出,该基金机构持有比例较大,个人持有者比例逐渐提升。
对于缺乏个股投资经验的朋友,这样一揽子的投资标的是不错的选择,节省费率的同时,也收获了近期热点的红利。不过在这里依然要注意仓位的管控,正如天咨之前分享过的,ETF其实已经不完全是风险分散的标的,它现在也已经成为情绪化的投资工具。尤其科技领域,震荡幅度较大,仓位上的把控尤其重要!
以上内容为天咨君近期的深入思考,如果您有什么好观点、好想法,欢迎在评论区留言,我们一起探讨。
$万家中证软件服务ETF发起式联接C(OTCFUND|018183)$

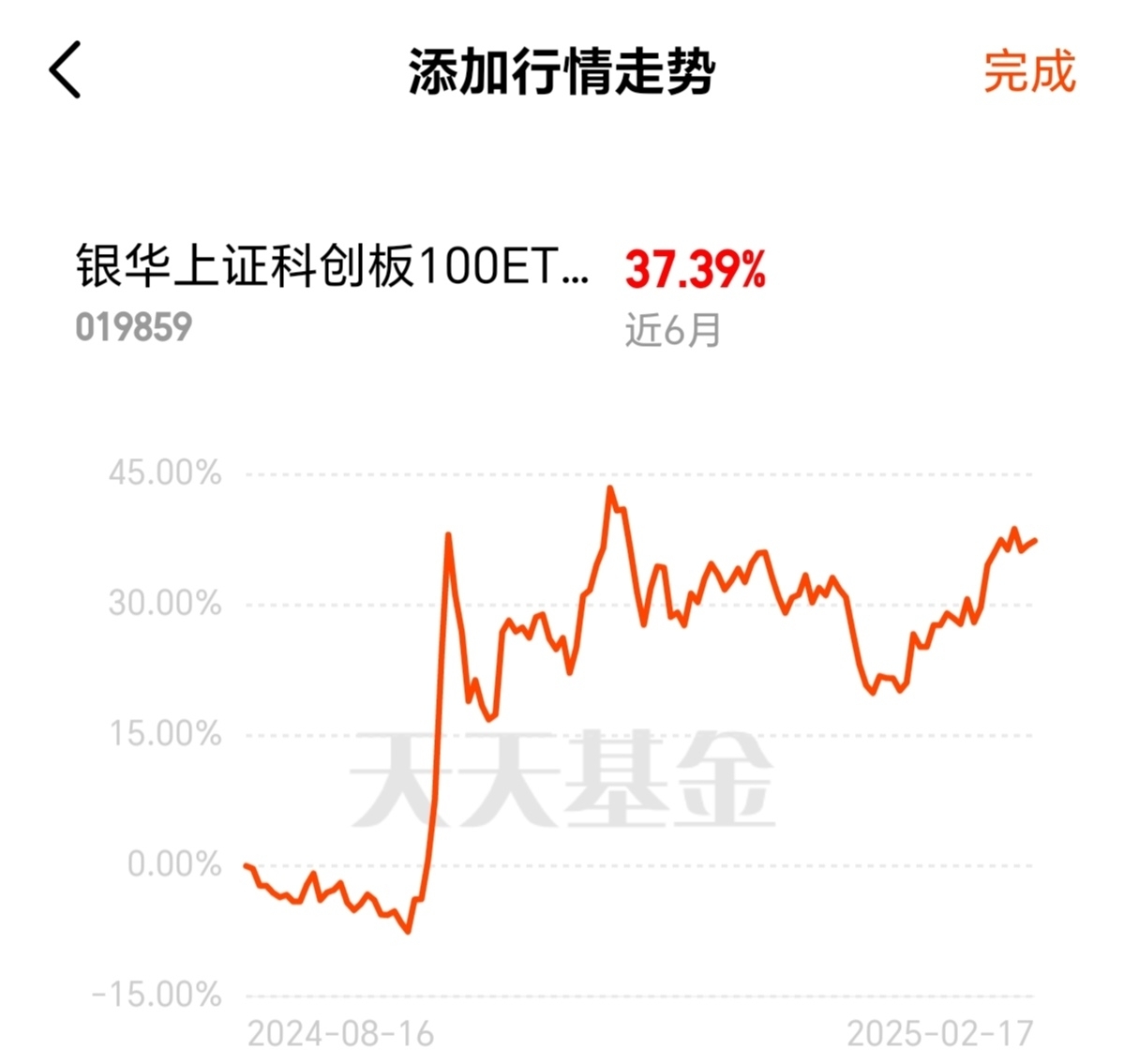

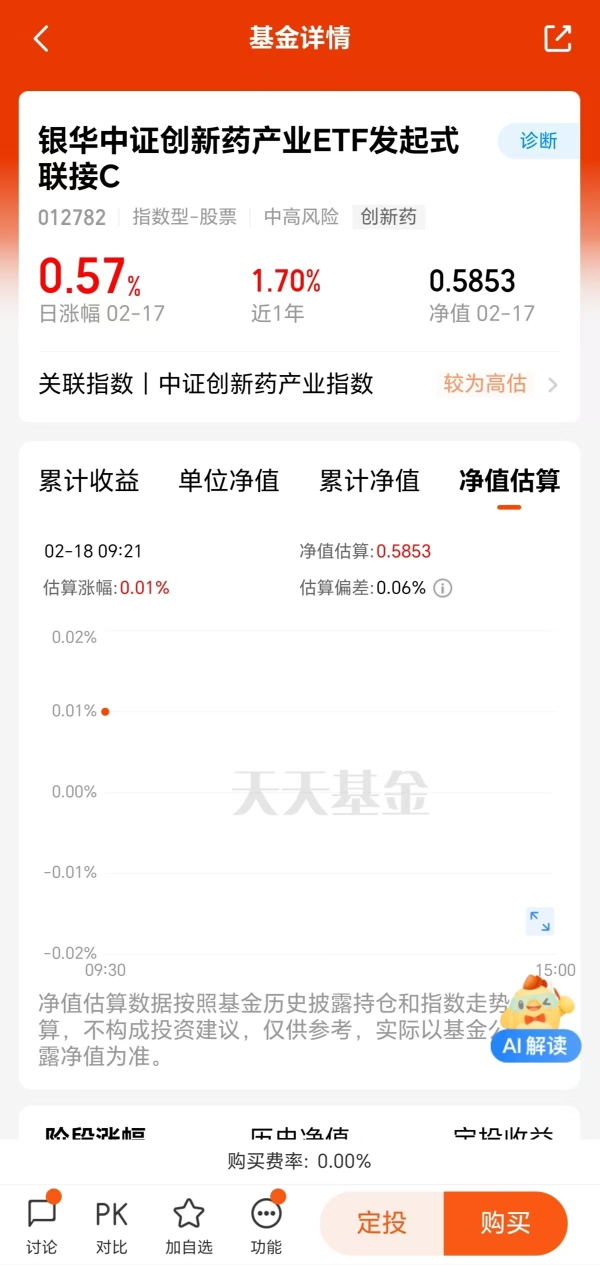
 感谢大佬支持
感谢大佬支持

